Introduction to Exalead Query Language

Contents
Query Parsing
The query parser is the component responsible for:
•Parsing the end-user query string into a structured query tree – the syntactic parsing step
•Expanding the user query through linguistic modules
•Providing some hooks to customize query handling
•Generating the index query
•Generating the highlighting and summarizing commands from the query string
Numerous configuration options are available and can be customized and extended.
Query tree
The internal representation of a parsed query is a tree where the inner nodes are query operators and the leaves are Boolean predicates.
The following query searches documents containing the words "Red Sox" or the words "Chicago bulls", and modified after the January 1st, 2007:
((Red Sox) OR (Chicago Bulls)) AND lastmodified>=2007/01/01
The query tree corresponding to this query is represented by the following diagram:
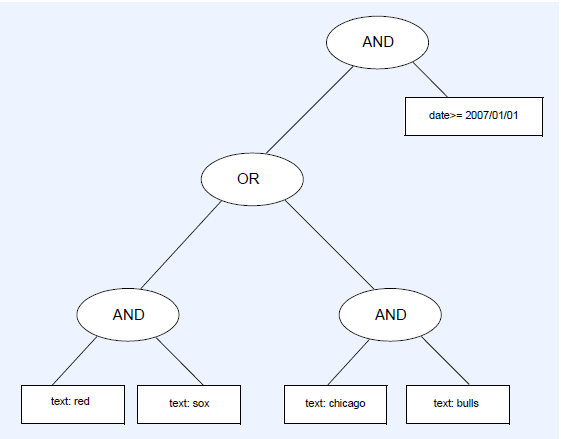
The Exalead query language provides various query operators (for the complete list of available operators, see Standard Query Operators), such as Boolean operators (AND, OR, NOT), word sequence operators (NEAR, PHRASE), score operators (MAX, MIN), etc.
The query tree is processed by query expansion modules to enrich (e.g. by using synonyms and semantics), interpret and normalize it (e.g. recognize city names or acronyms). Query expansion generates a new query tree. This is the query rewriting step. Note that after this step, all Leaf and Rex nodes in the tree have been converted to FinalLeaf nodes.
Options interpretation
Leaf nodes can have different prefixes. The following are supported:
• ‘-’ will cause the leaf to be included in a <NOT> context.
NOTE - ‘-’ is only interpreted at the beginning of a leaf. For example, Sarbanes-Oxley will be considered as a single leaf, while Sarbanes -Oxley will create two leaves, one of which will be negated.
• ‘+’ causes the leaf to be treated as exact, which disables some expansion operations.
• Non-whitespaces word separators (".", "&", "-", etc.) are interpreted as a NEXT operator instead of a AND, when they are used to separate words without additional whitespaces. For example, ASP.NET will be parsed as ASP NEXT NET instead of ASP AND NET.
• The query parser allows non-alphanumerical chars in words in a few special cases that can be configured.
Furthermore, leaves can have options. Options should be specified in brackets and separated by quotes. There are two kind of options:
• query rewrite options that modify the way the query parser works and expands this leaf
• raw options that will be passed to the index
Wildcard handling
If wildcard/prefix/sufffix parsing is enabled, they are expanded using a dictionary generated from the corpus. The dictionary is in the globaldict service. See documentation about linguistic services.
Prefix handlers
The main types of prefix handlers are:
•Linguistic handlers which modify linguistic handling options on their content. For example, soundslike:foo enables phonetic matching on foo. It is equivalent to writing foo{p} (see below).
•Target handlers which change the index field targeted by the search. for example title:foo could be defined to perform a standard text query on foo. You could also have categories:Top/Kind/Pdf which performs a category query that returns only PDF documents.
•Numeric handlers which perform a specific type of matching on their content. For example,
– size:42 could perform a numerical search on the index field size
– size>42 could perform a ranged search, or
•Custom handlers, which allow, through custom code, to completely take over the translation process.
Matching levels and generalization
Each word can exist in the index at several matching levels, also called index kinds. The matching method between word predicates and the document words is defined by the predicate's matching level. The matching level can be one of the following:
•Exact match: match only if the words match exactly, for example only The matches. This is known as kind 0.
•Case insensitive match: ignore case for matching, for example the and The match. This is known as kind 1. This level can be specified by the "i" option.
•Normalized match: ignore case and accents, for example the, thé and Thé match. This is known as kind 2.
•Lemmatized match: the word predicate matches the document's word if both words have the same lemmatization root (example: "protector" and "protecting"). Note that the lemmatization level also ignores letter cases and accents.
The default kind for word matches is normalized but this can be forced by options for predicates.
•It is also possible to define a second, larger matching level called the generalized level, which can be used to expand the query, while associating a smaller ranking weight to the matches for the generalized terms. For example, doing a case insensitive match with generalization to normalized will cause the and The to match with a high ranking weight and thé to match with a lower weight. The "g" option indicates the matching level used for the generalized terms, and the "f" option indicates the weight attenuation for the generalized terms. When using these options, the predicate is logically equivalent to a MAX expression combining the term and the generalized term. For example, the predicate interfaces{n,g=*,f=10} is logically equivalent to Thé{k=0,g=n} -->Thé{k=0} MAX thé{k=1,w/=10} MAX the{k=2,w/=100}
Availability of kinds 0, 1 and 2 depends on analysis configuration and whether the field was mapped as exact, normalized or lowercase. For all kinds to be available the word must be indexed in all forms.
Other custom kinds can be available if they have been generated by custom code. They can be queried by setting an explicit kind. This is useful for custom lemmatization behavior in k=3.
Query Execution
Each tree leaf is associated with the collection of documents for which the corresponding predicate is true. These document collections are enumerated in parallel, thus producing lists of documents which are combined w.r.t. the operators found in the query tree's inner nodes. For example, a OR operator will merge the underlying lists together, whereas a AND operator will retain only the documents found in all the underlying lists.
The document lists are combined recursively, up to the root node of the tree, and the final list obtained after processing the root node is the query's results set.
At the same time the documents lists are combined, the score values computed for each predicates are also merged together to compute the overall document score.
The search results score computation is not affected by the query refinements (i.e. the query predicates added internally when processing a refinement on a category or keyword have a null score weight). The purpose of query refinements is to select a relevant subset of the search results and to interactively navigate through the search results, without modifying the ordering of the selected results.
Relevancy scores
Whenever a document matches a query predicate, it is given a score value, computed by the following formula:
Si = Z(Ri)*Wi
where:
– Si is the score of the document for the i-th predicate
– Ri is the score class of the word's predicate, as defined in the document when it has been indexed
– Wi is the weight of the i-th predicate in the query
– Z is the mapping table between the index score classes and the query score values (the default value of Z is the identity function Z(x) = x)
This score value combines a ranking score that has been given to the document when it has been indexed (the Ri score class), a global query parameter set by the administrator to configure the relative weight of the index-time ranking score (the Z mapping table) and a per query term weight that is set when the query is executed (Wi).
The Wi value can be set explicitly for each query predicate by using the 'w' parameter in the score modifiers. In the following example, we set a term weight of 5000 for the word 'GUI' and of 1000 for the word 'design':
Si = Z(Ri)*Wi GUI{w=5000} AND design{w=1000}
When not specified, the default value of Wi is determined by the relative frequency of the query terms: the more frequent a word is, the less weighted it will be. The base weight is always 100000 for the rarest term. The default weight value of non-textual predicates (categories or numerical fields) is 0, so that without an explicit score modifier these predicates only affect the selection of matching documents, but do not have any influence on the ranking score.
For a complete list of the available score modifiers, see Score modifiers on page 38.
These score modifiers can be typically used to take control of the relative importance of each query term in the computation of the document relevancy. In the example given in section 1, the query expansion module would set a larger weight on the word 'GUI', which is the most meaningful in the user's query, and a light weight on 'design' and the associated synonyms, since this word is less relevant. This would give the following weighted query:
((Graphical{w=20000} AND User{w=50000} NEAR Interface{w=50000}) OR
GUI{w=100000})
AND
(design{w=10000} OR conception{w=10000})
Calculating the document score
Most query operators simply add the score values of their underlying predicates, but some operators like MAX or MIN apply a different operation. Please refer to the operator details below for information on the score value combination operated by the different query operators.
The final ranking score computed after combining the score values of all the matching predicates is then added with two other score values assigned globally to the matching document:
•A 'proximity bonus' computed by analyzing the relative position of the query terms in the matching document (a document where the query terms are close to each others will receive a larger bonus than a document where the query terms are far)
•A ‘static ranking expression’, which is a value computed from arbitrary hit fields and user context, using the virtual fields syntax (this score can for example be used to give a bonus value to the known 'popular' documents in the indexed corpus)
The relative weight of the proximity bonus in the final score are configured in the search manager configuration.